Problem
The V1 of my AWS Clean Architecture Starter Kit needed a persistence layer.
My original plan was to use EF Core as I normally would.
That plan ended very quickly when I discovered EF Core does not support DynamoDB.
DynamoDB is AWS’s fully managed serverless NoSQL database service. It offers automatic scaling, high availability, and a flexible schema model that makes it a popular choice for serverless architectures.
I wanted to build a Clean Architecture solution hosted on AWS Lambda, deployed with CDK, and backed by DynamoDB.
What I expected to be a straightforward persistence change turned into a much larger architectural challenge.
Original architecture
What I had in mind was a focused and opinionated Clean Architecture solution built around serverless AWS services.
The architecture consisted of:
- AWS Lambda hosting the API
- API Gateway routing requests
- DynamoDB providing persistence
- AWS CDK managing infrastructure*
The codebase itself was intended to remain relatively simple:
- Core containing entities and business rules
- Infrastructure handling persistence concerns
- IaC isolated in a dedicated CDK project
At this point I assumed the persistence technology could be swapped without affecting the architecture significantly.
It was also planned to use my small Repository Pattern package, Ghanavats.Repository, which I originally created to centralise common persistence functionality and hide implementation details behind simple abstractions.
Repository package
The purpose of the package was simple.
Hide persistence concerns behind common abstractions so the rest of the application remains unaware of the underlying database implementation.
The package currently provides implementations built around EF Core’s DbContext.
In theory, this should have made swapping persistence technologies easier.
In practice, it did not.
Why I thought it would work
My first instinct was to extend the existing Repository package and add DynamoDB support behind the same abstractions.
The idea seemed reasonable.
I already had abstractions such as:
public interface IRepository<T> : IReadRepository<T>
where T : class
Why not provide another implementation?
The problem was that the abstractions had been designed around EF Core’s way of querying and working with data.
I spent a lot of time trying to force the existing abstractions to work.
The more I pushed in that direction, the more friction I created.
Some repository methods simply did not map cleanly to DynamoDB operations.
What looked like a generic abstraction was actually carrying assumptions from EF Core.
IAmazonDynamoDB vs DynamoDBContext
This was another point of confusion.
AWS provides multiple ways to interact with DynamoDB.
The two options I spent most of my time evaluating were:
IAmazonDynamoDBDynamoDBContext
The low-level interface is exposed through IAmazonDynamoDB.
This API maps very closely to DynamoDB’s underlying operations and gives complete control over requests and responses.
A simplified example looks like this:
internal sealed class PeopleRepository : IPeopleRepository
{
private readonly IAmazonDynamoDB _dynamoDb;
public PeopleRepository(IAmazonDynamoDB dynamoDb)
{
_dynamoDb = dynamoDb;
}
public async Task<Person> GetPersonById(Guid personId)
{
var getItemRequest = new GetItemRequest
{
TableName = "Person",
Key = new Dictionary<string, AttributeValue>
{
{ "PersonId", new AttributeValue { S = personId.ToString("D") } }
}
};
var result = await _dynamoDb.GetItemAsync(getItemRequest);
var personIdMapped = result.Item["PersonId"].S;
var somePropertyMapped = result.Item["SomeProperty"].S;
var person = Person.Create(personIdMapped, somePropertyMapped);
return person;
}
}
While powerful, this approach introduces a lot of manual mapping code.
The alternative is DynamoDBContext.
This high-level interface acts as a wrapper around IAmazonDynamoDB and handles much of the mapping logic automatically.
A simplified example:
internal sealed class PeopleRepository : IPeopleRepository
{
private readonly DynamoDBContext _dbContext;
public PeopleRepository()
{
var clientConfig = new AmazonDynamoDBConfig
{
RegionEndpoint = RegionEndpoint.EUWest1
};
var client = new AmazonDynamoDBClient(clientConfig);
_dbContext = new DynamoDBContextBuilder()
.WithDynamoDBClient(() => client)
.Build();
}
public async Task<Person> GetPersonById(Guid personId)
{
var result = await _dbContext.LoadAsync<DynamoDbPerson>(personId.ToString("D"));
return result.ToDomain();
}
}
After experimenting with both approaches, DynamoDBContext felt like the better fit for the starter kit.
Mapping challenge
This is where things became interesting.
With EF Core, I typically keep persistence concerns out of the domain and configure mappings through the Fluent API inside DbContext.
DynamoDBContext takes a different approach.
Entities need to be decorated with attributes so DynamoDB knows how to map them correctly.
Examples include:
DynamoDBTableDynamoDBHashKeyDynamoDBProperty
Adding these attributes directly to my domain entities would have introduced a dependency from the Core layer to the AWS SDK.
That would violate one of the design principles I wanted the template to enforce.
The challenge was no longer DynamoDB itself.
The challenge was introducing DynamoDB without leaking AWS-specific concerns into the Core layer.
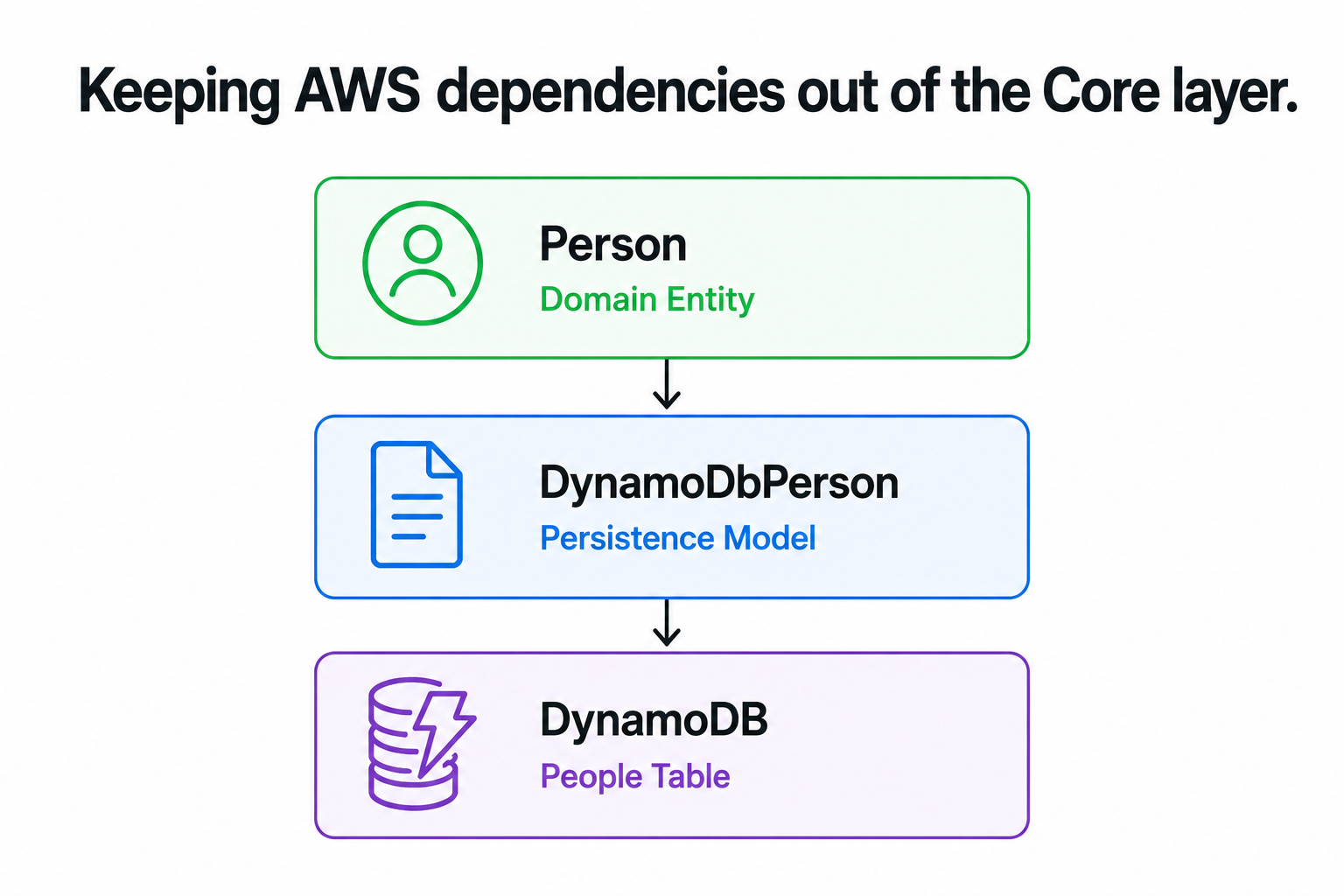
Persistence model solution
Eventually I stopped fighting the SDK.
I decided to:
- Use
DynamoDBContext - Implement a dedicated repository in Infrastructure
- Keep the domain model unchanged
- Introduce a dedicated persistence model for DynamoDB mapping
Rather than forcing DynamoDB to fit my existing Repository package, I introduced a DynamoDB-specific persistence model.
Example:
[DynamoDBTable("People")]
internal sealed class DynamoDbPerson
{
[DynamoDBHashKey]
public string PersonId { get; init; } = string.Empty;
[DynamoDBProperty]
public string Name { get; init; } = string.Empty;
[DynamoDBProperty]
public string Email { get; init; } = string.Empty;
[DynamoDBProperty]
public string Phone { get; init; } = string.Empty;
[DynamoDBProperty]
public string DateOfBirth { get; init; } = string.Empty;
}
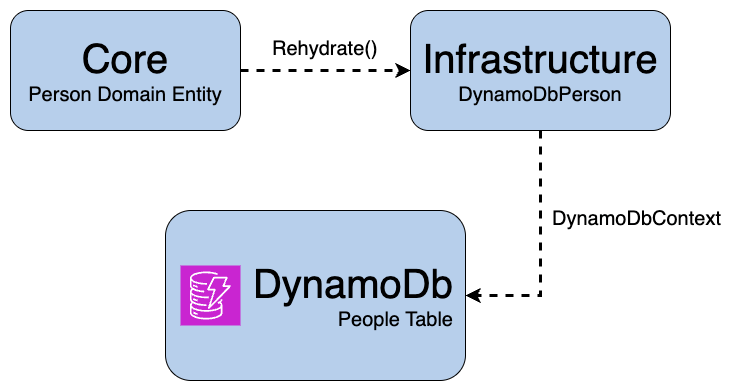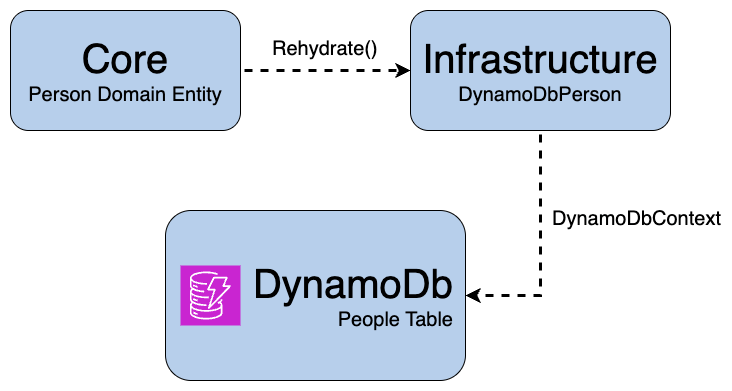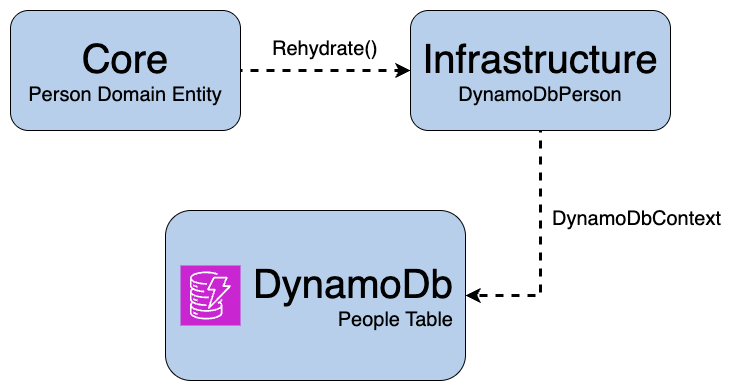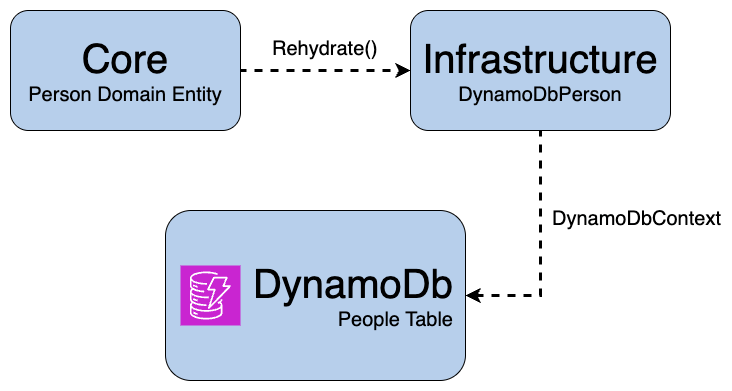
This allowed the Infrastructure layer to own all DynamoDB-specific concerns while keeping the Core project free from AWS dependencies.
To recreate domain entities from persistence models, I introduced a hydration factory:
public static Person Rehydrate(
Guid id,
string name,
string email,
string phone,
string dateOfBirth)
{
return new Person(id, name, email, phone, dateOfBirth);
}
And a mapper:
internal static class PersonMapper
{
extension(DynamoDbPerson? source)
{
public Person? ToDomain()
{
if (source is null)
{
return null;
}
return Person.Rehydrate(
Guid.Parse(source.PersonId),
source.Name,
source.Email,
source.Phone,
source.DateOfBirth);
}
}
}
The final design ended up being much simpler than my original approach.
Instead of introducing AWS-specific dependencies into the Core layer, I created a dedicated persistence model in Infrastructure and mapped it to the domain entity.
This implementation is now part of the AWS Clean Architecture Starter Kit and will likely evolve as I gain more experience with DynamoDB.
Lessons learned
Not every abstraction survives a change in persistence technology.
I expected my repository package to hide DynamoDB in the same way it hid EF Core. In reality, DynamoDB introduces different access patterns and assumptions.
Clean Architecture is more about dependency direction than specific technologies.
The biggest challenge was not DynamoDB itself. It was preventing AWS-specific concerns from leaking into the Core layer.
Sometimes a dedicated implementation is simpler than a generic abstraction.
I spent a considerable amount of time extending an existing repository package before realising a small, focused DynamoDB implementation was easier to understand and maintain.
Persistence models and domain models do not always have to be the same thing.
Introducing a DynamoDB-specific persistence model allowed me to keep the domain clean while still benefiting from DynamoDBContext and its attribute-based mapping.
Conclusion
If I were starting this implementation again today, I would still choose DynamoDBContext and a dedicated persistence model.
The solution ended up being much simpler than the repository abstraction I originally tried to preserve.
Sometimes the best architectural decision is not finding a way to keep an abstraction alive.
Sometimes it is recognising when it no longer fits the problem you are trying to solve.